
What is IndexCache? Accelerating Long-Context LLMs
- Publised April, 2026
-
Duc Nguyen (Dwight)
Discover how IndexCache accelerates sparse attention in LLMs. Learn its cross-layer index reuse mechanism, deployment methods, and ROI for enterprise AI.
Table of Contents
Toggle Key Takeaways
Massive Compute Reduction: IndexCache eliminates up to 75% of indexer computations in sparse attention models without degrading output quality.
Flexible Deployment: Enterprise teams can adopt IndexCache via a “Training-Free” greedy search method or a “Training-Aware” multi-layer distillation approach.
Ideal for Enterprise Workloads: Delivers ~20% cost reductions in production for long-context tasks like Retrieval-Augmented Generation (RAG), document analysis, and multi-step agentic workflows.
Introduction
The evolution of Large Language Models (LLMs) has reached a critical inflection point. As enterprises rapidly transition from basic conversational bots to complex, autonomous multi-agent systems, the demand for massive context windows has skyrocketed. Whether analyzing a 300-page legal contract, processing financial data through Retrieval-Augmented Generation (RAG), or executing long chain-of-thought reasoning, these models must ingest hundreds of thousands of tokens. However, this demand introduces severe computational bottlenecks, specifically regarding the quadratic scaling of self-attention mechanisms.
To solve this, researchers recently introduced IndexCache, a groundbreaking sparse attention optimizer. By identifying and eliminating redundant computations across network layers, IndexCache fundamentally alters the economics and speed of long-context AI inference.
For enterprise AI teams, software architects, and machine learning engineers seeking to scale inference efficiently, understanding IndexCache is no longer optional – it is a competitive necessity. This comprehensive guide explores the architecture of IndexCache, how it resolves existing bottlenecks, its two primary deployment pathways, and the direct ROI it brings to enterprise AI ecosystems.
What is IndexCache and How Does it Solve the Bottleneck?
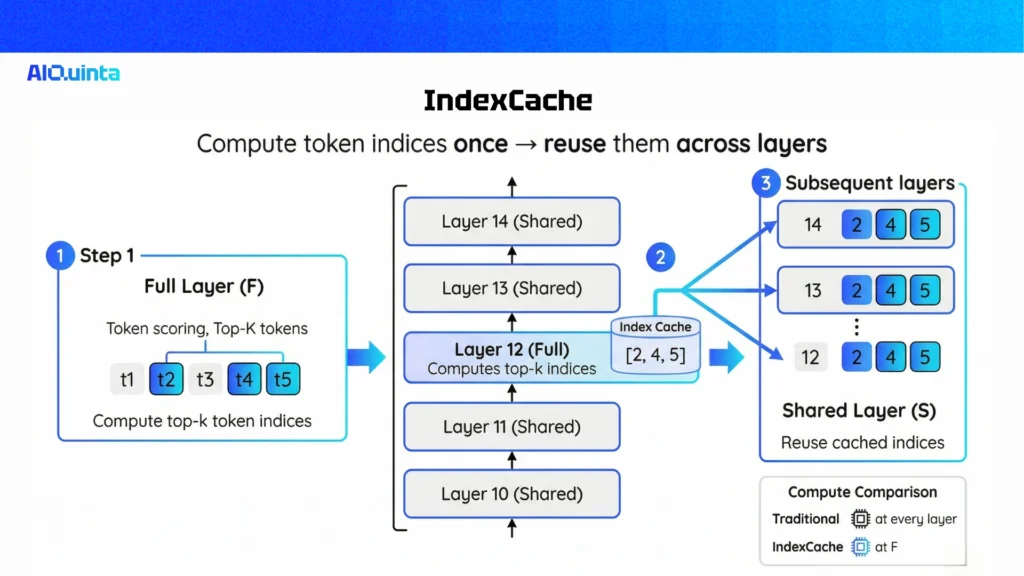
IndexCache attacks the computational inefficiency of the indexer module. The researchers behind this technique uncovered a profound insight: token selection patterns exhibit massive redundancy across consecutive transformer layers. If Layer 12 and Layer 13 of an LLM are largely selecting the exact same top-k tokens as being “important,” recalculating these scores independently for Layer 13 is a waste of compute.
The Core Concept: Cross-Layer Index Reuse
IndexCache exploits this cross-layer redundancy. Rather than forcing every transformer layer to compute fresh indices, IndexCache allows subsequent layers to “inherit” or reuse the token indices calculated by earlier layers. By caching the index outputs (not just the KV values), the overall indexer cost plummets from scaling across all layers to a mere fraction of the model.
Full (F) Layers vs. Shared (S) Layers
To implement this structurally, IndexCache partitions the architecture into two distinct types of layers:
Full (F) Layers: These act as “anchor” layers. They retain their active lightning indexers, fully scoring the tokens, computing the mathematical operations, and choosing the most important tokens to cache.
Shared (S) Layers: These layers are stripped of their indexing computations. During inference, when the model hits an S layer, it bypasses the heavy math and simply copies the cached top-k indices from the nearest preceding F layer.
During active inference, this introduces only a single conditional branch in the code: If F layer, compute; if S layer, copy.
Compare: IndexCache vs. KV Cache Compression / Optimization
| Feature | KV Cache Compression / Optimization | IndexCache |
|---|---|---|
|
Primary Goal |
Reduce memory footprint (VRAM capacity). |
Reduce computational load (FLOPs). |
|
Mechanism |
Shrinks or manages the physical size of the stored key-value states. |
Skips redundant token-scoring calculations entirely across layers. |
|
Impact |
Allows larger batch sizes; prevents out-of-memory (OOM) errors. |
Directly speeds up Time-to-First-Token (TTFT) and throughput. |
|
Compatibility |
Operates on the storage/memory layer. |
Operates on the arithmetic logic layer. Fully complementary with KV Cache optimization. |
IndexCache is not a traditional memory compression tactic. It attacks the compute bottleneck, meaning an enterprise can run IndexCache alongside existing PagedAttention or KV-quantization frameworks to maximize hardware utilization from both ends.
How to Implement IndexCache in Production
Recognizing that enterprise AI teams operate with varying degrees of control over their models – from API -level tweaking to full foundational model pre-training – the creators of IndexCache designed two distinct pathways for implementation.
Training-Free IndexCache (The Immediate Fix)
For teams relying on off-the-shelf, pre-trained DSA models, updating weights is often unfeasible or too expensive. The Training-Free approach allows organizations to apply IndexCache dynamically.
However, simply alternating layers blindly (e.g., F, S, F, S) degrades the model’s output quality, as some layers are fundamentally more critical for reasoning than others. To solve this, the researchers utilize a greedy layer selection algorithm.
How it works:
The model is fed a small, domain-specific calibration dataset.
The algorithm evaluates language modeling loss.
It iteratively converts F layers to S layers, permanently retaining indexers only in the layers that mathematically minimize the degradation of the model’s output.
Best Practice: Enterprises should use internal, domain-specific data (e.g., proprietary financial logs or legal repositories) for the calibration set. This ensures the resulting layer-sharing pattern is hyper-optimized for the specific workloads the business actually executes.
Training-Aware IndexCache (The Foundational Approach)
For organizations with the budget and infrastructure to pre-train or heavily fine-tune their foundation models, the Training-Aware approach yields superior, more stable results.
This method introduces a Multi-Layer Distillation Loss during the training phase. Standard training treats every indexer as an isolated unit. Training-aware IndexCache forces a paradigm shift: it trains each retained indexer (F layer) to predict a “consensus” subset of tokens that will be highly relevant not just for itself, but for all the subsequent S layers it serves.
How it works:
By averaging the attention distributions across the served layers, the F layer learns to select tokens that satisfy the structural needs of the entire block. Because the model natively understands how to share indices from the ground up, enterprises can aggressively prune indexers (using simple uniform interleaving) while matching the exact accuracy of full-indexer architectures.
Benchmark Performance and Enterprise ROI
When evaluating new AI optimizations, the metrics that matter to the C-suite are throughput latency and deployment cost. IndexCache delivers compelling returns on both fronts, particularly for models operating at 30B parameters and scaling up to 200K token contexts.
Throughput and Latency Improvements
Benchmarking on long-context workloads demonstrates that aggressively pruning the model to retain only 25% of its indexers (eliminating 75% of indexer compute) yields:
1.82x Speedup in Prefill Latency: Time-to-first-token drops dramatically. In test cases, a 19.5-second wait time was slashed to just 10.7 seconds.
1.48x Improvement in Decode Throughput: Token generation speeds increased from 58 to 86 tokens per second per request.
Total Throughput Increases: Even when the KV cache reaches saturation limits, IndexCache sustains a 1.51x overall throughput increase.
Ideal Use Cases for Enterprise Value
While short-context queries (under 2,000 tokens) see marginal speedups of around 5%, the return on investment scales exponentially with sequence length.
Document Analysis & E-Discovery: Processing massive internal knowledge bases or regulatory filings becomes nearly twice as fast.
Retrieval-Augmented Generation (RAG): AI models can ingest a larger array of vectorized chunks simultaneously without locking up the compute cluster, leading to richer, more accurate responses.
Multi-Step Agentic Workflows: Autonomous agents that write code, verify execution, and loop back through extensive logs require maintaining long contexts. IndexCache reduces the latency bottlenecks that traditionally make these loops feel sluggish in production.
Ultimately, enterprise implementers report an approximate 20% reduction in deployment costs for these long-context architectures due to the reduction in required FLOPs per query.
Limitations and Future Considerations
While highly effective, IndexCache is not devoid of limitations. The researchers noted that at extremely aggressive retention ratios – such as keeping only 1/8th of the indexers (87.5% sparsity) – the model begins to suffer substantial quality degradation. There is a fundamental mathematical limit to cross-layer stability; eventually, the semantic requirements shift too drastically for layers to share indices.
Furthermore, the Training-Free approach is highly sensitive to the calibration data. If an enterprise calibrates the greedy search on conversational data but deploys the model for Python code generation, the shared patterns will misalign, causing hallucination or logic failures.
Conclusion
The release of IndexCache signals a critical maturation in how the AI industry approaches long-context optimization. By shifting the focus from memory compression to algorithmic compute reduction via cross-layer index reuse, organizations can finally unlock the true potential of ultra-long context windows without exorbitant cloud compute bills. Whether applied retroactively via greedy search algorithms or integrated structurally through multi-layer distillation, IndexCache provides a robust, production-ready pathway to faster, more cost-effective enterprise AI.
More about the research: IndexCache: Accelerating Sparse Attention via Cross-Layer Index Reuse
FAQs
Does IndexCache replace standard KV Cache compression techniques?
No. IndexCache is not a traditional memory compression tactic. It attacks the compute bottleneck, meaning an enterprise can run IndexCache alongside existing PagedAttention or KV-quantization frameworks to maximize hardware utilization from both ends.
How much faster will my model run with IndexCache?
The speedup is highly dependent on context length. For extremely short prompts, the speedup is minimal (~5%). However, for long-context workloads approaching 200,000 tokens, IndexCache can deliver up to an 82% improvement in time-to-first-token and a nearly 50% boost in decode throughput.
How do I implement the Training-Aware version of IndexCache?
Implementing Training-Aware IndexCache requires access to the model’s training loop. You must introduce a multi-layer distillation loss function during the pre-training or fine-tuning phase. This forces the retained “Full” layers to optimize their token selection based on the averaged attention distributions of the “Shared” layers they will be serving in production.
Turn Enterprise Knowledge Into Autonomous AI Agents
Your Knowledge, Your Agents, Your Control
Your Knowledge, Your Agents, Your Control
Latest Articles






