
Google’s TurboQuant: A Turning Point in AI Efficiency
- Publised April, 2026
-
Duc Nguyen (Dwight)
Google’s TurboQuant revolutionizes AI with 6x KV cache compression and 8x speed gains. Discover how this training-free algorithm enables “lossless” 3-bit AI inference.
Table of Contents
Toggle Key Takeaways
Massive Efficiency: TurboQuant reduces Key-Value (KV) cache memory usage by 6x and boosts attention computation speed by up to 8x.
Lossless Precision: Unlike traditional quantization, TurboQuant achieves “quality neutrality,” maintaining accuracy even at 3-bit precision.
No Retraining Required: It is a software-based, training-free algorithm that works out-of-the-box with models like Llama, Mistral, and Gemma.
The “Memory Tax” Solution: By eliminating the need for expensive quantization constants, it solves the overhead bottleneck that previously crippled long-context AI.
Hardware Impact: Optimized for NVIDIA H100 GPUs, it shifts the focus from raw hardware expansion to algorithmic optimization.
The Efficiency Paradox: Why TurboQuant Matters Now
Artificial intelligence has spent the last decade scaling through brute force: bigger models, more GPUs, and exponentially larger datasets. But as generative AI systems move from research labs into real-world deployment, infrastructure efficiency has become the industry’s most pressing challenge.
Google’s TurboQuant represents a fundamental step in solving that problem.
Rather than improving raw compute power, TurboQuant attacks one of the largest hidden bottlenecks in modern AI systems: memory usage during inference. By compressing internal model memory without sacrificing accuracy, this breakthrough could dramatically lower the cost and complexity of deploying large AI systems.
For enterprises building AI platforms, the implications extend far beyond performance improvements. TurboQuant signals the start of a new phase in AI development where algorithmic efficiency becomes a primary competitive advantage.
What is TurboQuant?
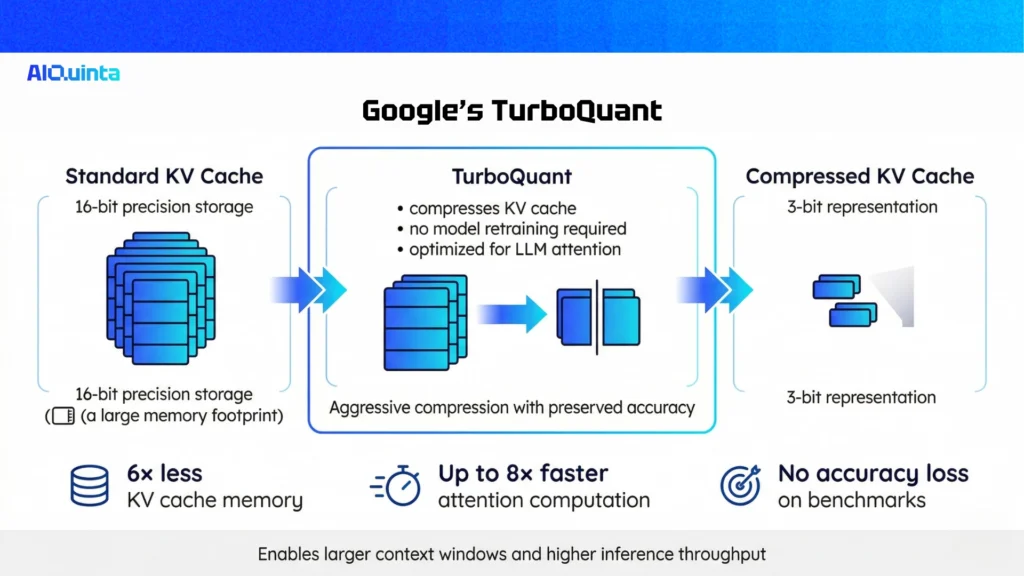
TurboQuant is a post-training quantization algorithm developed by Google Research designed to compress the KV cache used during large language model inference. Its core objective is simple:
Compress the KV cache aggressively while preserving model accuracy.
Instead of storing intermediate values at 16-bit precision, TurboQuant compresses them down to 3 bits per value without retraining the model. In benchmark testing, the results are significant:
- 6× reduction in KV cache memory
- Up to 8× faster attention computation
- No measurable accuracy degradation on major benchmarks
These improvements enable AI systems to run larger context windows and serve more users simultaneously.
Performance Benchmarks: 8x Faster, 6x Smaller
Google’s research, tested on H100 GPUs and open-source models like Llama-3.1-8B, shows staggering results:
| Metric | Traditional Quantization (4-bit) | Google TurboQuant (3.5-bit) |
|---|---|---|
|
Memory Reduction |
2-3x |
6x |
|
Attention Speedup |
~2x |
8x |
|
Accuracy Loss |
Common (Logic degradation) |
Zero (Lossless) |
|
Overhead |
High (Scaling constants) |
Zero |
|
Training Needs |
Often requires calibration |
None (Plug-and-play) |
In long-context benchmarks, TurboQuant achieved perfect recall. It found a single specific sentence hidden within 100,000 words—a feat usually reserved for uncompressed, memory-heavy models.
How TurboQuant Works: The Two-Stage Mathematical Shield
The brilliance of TurboQuant lies in its two-stage design, which combines geometric transformation with error correction.
PolarQuant Compression
The first stage transforms the mathematical representation of vectors. Instead of storing vectors in standard Cartesian coordinates, TurboQuant rotates them into polar form, which distributes information more evenly across dimensions.
This transformation allows a highly efficient quantization process where each component can be compressed with minimal information loss.
Key benefits:
- reduced redundancy in vector representation
- improved compression efficiency
- removal of normalization overhead
This stage performs the majority of the compression.
Quantized Johnson-Lindenstrauss (QJL)
After compression, a small amount of residual error remains. TurboQuant uses a second algorithm called Quantized Johnson-Lindenstrauss (QJL) to correct this error.
The QJL step:
- projects the residual error into a lower-dimensional space
- stores only a single sign bit (+1 or −1) per value
- removes systematic bias in attention calculations
This clever step ensures that the model maintains accurate attention scores even with extremely compressed data.
The result is a compression technique that maintains statistical accuracy while dramatically reducing memory requirements.
Why This is a "Turning Point" for Enterprise AI
TurboQuant isn’t just a technical whitepaper; it’s a strategic pivot for the entire AI ecosystem.
Democratizing Large Models
Previously, running a 70B or 400B model required an enterprise-grade data center. By slashing the memory footprint 6x, TurboQuant allows these models to run on significantly cheaper hardware or even “on-device” (high-end smartphones and laptops).
Enabling “Agentic” Workflows
AI Agents (which perform multi-step tasks) require massive context windows to remember previous tool calls. TurboQuant makes these “long-memory” agents economically viable for the first time by reducing the cost-per-token of long-context inference.
The Market Shift: Software vs. Hardware
The day TurboQuant was detailed, memory chip stocks saw immediate volatility. The message was clear: Efficiency is the new scale. We are entering an era where algorithmic breakthroughs can offset the need for multi-billion dollar hardware clusters.
Comparison: TurboQuant vs. GPTQ and AWQ
While popular methods like GPTQ or AWQ are staples in the open-source community, they have limitations that TurboQuant bypasses:
Calibration: GPTQ requires a calibration dataset; TurboQuant is “data-oblivious” and works instantly.
Bit-Width Limits: Most methods see sharp accuracy drops below 4 bits. TurboQuant remains stable at 3 bits.
Vector Search: TurboQuant is optimized for semantic search engines, achieving higher recall than Product Quantization (PQ) with zero indexing time.
Conclusion: The Future of Efficient AI
Google’s TurboQuant marks the end of the “efficiency tax” in AI. By proving that we can compress data to 3 bits without losing intelligence, Google has provided a roadmap for sustainable AI growth. For enterprises, this means lower cloud bills and faster apps. For the industry, it means the next evolution of AI won’t just be bigger—it will be significantly smarter about how it uses every single bit.
More information by Google Research: TurboQuant: Redefining AI efficiency with extreme compression
FAQs
What is Google TurboQuant?
TurboQuant is a compression algorithm developed by Google Research that reduces the memory usage of large language models by compressing their key-value cache during inference.
Does TurboQuant require me to retrain my existing AI models?
No. TurboQuant is a training-free, “plug-and-play” algorithm. It can be applied to the inference phase of existing Large Language Models (LLMs) without any fine-tuning or calibration.
What technologies power TurboQuant?
TurboQuant combines two core methods: PolarQuant for vector compression and Quantized Johnson-Lindenstrauss (QJL) for residual error correction.
Turn Enterprise Knowledge Into Autonomous AI Agents
Your Knowledge, Your Agents, Your Control
Your Knowledge, Your Agents, Your Control
Latest Articles






