
BookRAG vs RAG: Key Differences in AI Retrieval Systems
- Publised March, 2026
-
Duc Nguyen (Dwight)
BookRAG vs RAG: Understand the key differences, architectures, use cases, and when to deploy each approach in enterprise AI systems.
Table of Contents
Toggle
Key Takeaways
- Traditional RAG relies on flat text chunking and semantic vector search, which often causes information fragmentation and loss of context in long, complex documents.
- BookRAG is a novel, structure-aware framework designed for hierarchically organized texts like books, manuals, and handbooks.
- BookIndex Core: BookRAG introduces a unified document representation combining a logical tree (Table of Contents) and an entity knowledge graph.
- Dynamic Workflows: Unlike RAG’s static pipeline, BookRAG utilizes an agent-based approach inspired by Information Foraging Theory to dynamically adjust retrieval strategies based on query complexity.
- Efficiency & Accuracy: BookRAG significantly improves retrieval recall and multi-hop reasoning accuracy while lowering token consumption compared to standard RAG models.
What is Traditional RAG (Retrieval-Augmented Generation)?
RAG (Retrieval-Augmented Generation) is an architecture that enhances large language models (LLMs) by injecting external knowledge at query time. Instead of relying solely on pre-trained weights, the system retrieves relevant documents and feeds them into the model as context.
How Standard RAG Works
In a conventional RAG pipeline, the system ingests unstructured text and processes it through a highly linear workflow:
Parsing & Chunking: The document is broken down into fixed-size text chunks (e.g., 500 or 1000 tokens) with a slight overlap to preserve immediate local context.
Embedding: Each chunk is converted into a high-dimensional vector representation using an embedding model.
Vector Search: When a user queries the system, the query is embedded, and a similarity search (like cosine similarity) retrieves the top-K closest matching chunks from a vector database.
Generation: The LLM synthesizes an answer based solely on the retrieved text snippets and the user’s prompt.
Read more: What is a Vector Database? How does it work
Limitations of Flat Chunking
While standard RAG is fast, easy to deploy, and highly effective for short documents or distinct FAQs, it suffers from severe drawbacks when applied to long-form, complex text:
Structural-Semantic Mismatch: Slicing a textbook into arbitrary 500-token chunks destroys the logical hierarchy. A subsection’s meaning is often tied to its parent chapter, which standard RAG fails to capture.
Information Fragmentation: Entities (like a character in a novel or a specific variable in an engineering manual) are scattered across hundreds of disconnected chunks.
Inflexible Pipelines: Standard RAG uses the same top-K retrieval method regardless of whether the user asks a simple fact-retrieval question (“Single-hop”) or requires document-wide summarization (“Global Aggregation”).
What is BookRAG?
Introduced in late 2025, BookRAG (Hierarchical Structure-aware Index-based Approach) is a specialized framework designed explicitly to address QA over complex documents. Instead of stripping a document of its inherent layout, BookRAG weaponizes the document’s structure to guide the AI’s retrieval process.
The Concept of BookIndex (Tree + Graph)
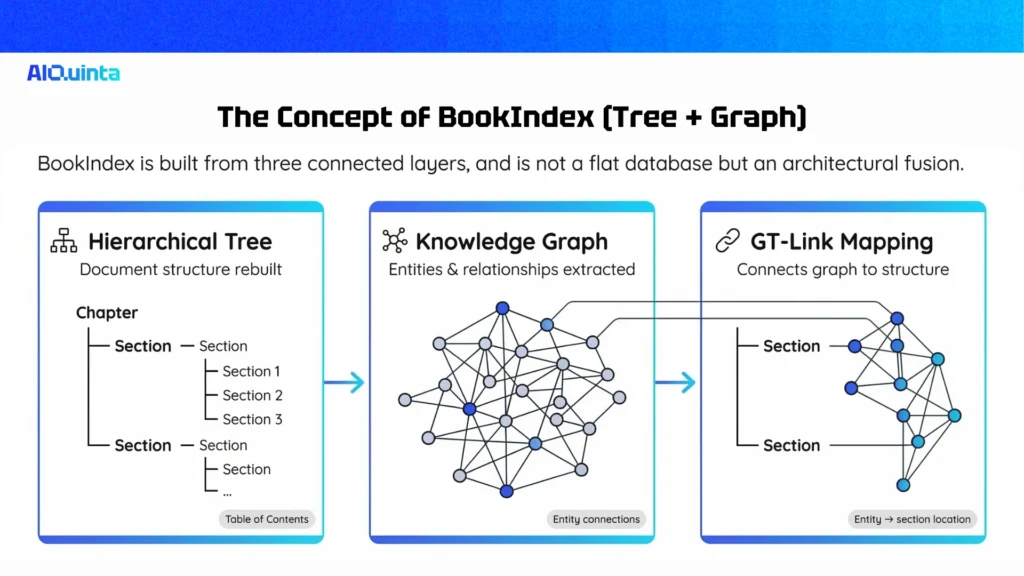
The heart of BookRAG is the BookIndex, a native data structure that refuses to flatten content. It represents the document using three core components:
- The Hierarchical Tree: The system uses layout parsers and LLMs to rebuild the document’s logical “Table of Contents.
- The Knowledge Graph: Within these blocks, LLMs extract fine-grained entities and their relationships, creating an entity graph.
- The GT-Link: A mapping function connects every entity in the graph directly to the tree nodes (sections) where it appears. This means the AI knows exactly where in the book’s hierarchy an entity lives.
Agent-Based Dynamic Retrieval
BookRAG moves away from “dumb” similarity search by utilizing an LLM agent inspired by Information Foraging Theory (IFT). Much like an animal hunting for food in patches, the BookRAG agent sniffs out “information patches” dynamically:
Query Categorization: The agent classifies queries into Single-hop, Multi-hop, or Global without relying on rigid probability scores.
Operator Workflow: Based on the query, it formulates a unique retrieval plan using operators (e.g., Selector to narrow down sections, Reasoner to perform multi-hop graph inference, and Skyline_Ranker to filter nodes based on both semantic relevance and structural importance).
BookRAG vs RAG: Core Differences Analyzed
Understanding the difference between BookRAG and traditional RAG is crucial for architects building enterprise AI solutions. Below is a deep dive into the comparative metrics.
Structural Understanding
Traditional RAG: Views documents as a bag-of-chunks. If a table spans two pages, or a crucial premise is established in Chapter 1 but referenced in Chapter 5, flat RAG struggles to bridge the gap.
BookRAG: Maps the exact layout of the document. If a query asks about a subsection, BookRAG can traverse up the tree to pull in the overarching chapter context, ensuring the LLM understands the broader theme.
Query Flexibility and Workflow
Traditional RAG: Employs a static, “one-size-fits-all” retrieval pipeline. Every prompt goes through the same embedding and vector distance calculation.
BookRAG: Highly modular. If you ask a “Global” question (e.g., “Summarize the overarching theme of this textbook”), the agent triggers different operators than it would for a “Single-hop” question (e.g., “What is the formula on page 42?”). It dynamically adapts to the cognitive load of the prompt.
Token Efficiency and Computational Cost
Traditional RAG: Can become incredibly token-heavy and expensive when attempting to solve multi-hop questions. Systems often have to retrieve massive context windows (sometimes retrieving 20+ chunks) just to hope the right answer is buried within.
BookRAG: Demonstrates competitive efficiency. By traversing the logical BookIndex tree, it prunes irrelevant branches early in the retrieval phase. Experimental benchmarks on MMLongBench show BookRAG reducing token consumption by an order of magnitude compared to exhaustive extraction techniques, because it only pulls highly targeted, logically verified nodes.
Accuracy in Complex QA
Traditional RAG: Often falls victim to the “Lost in the Middle” phenomenon and struggles heavily with multi-hop reasoning.
BookRAG: Achieves state-of-the-art performance on benchmarks like M3DocVQA and Qasper. By leveraging the entity graph and structural tree, it boasts high retrieval recall (upwards of 71% on complex documents) and significantly higher Exact Match rates.
| Feature / Capability | Traditional RAG | BookRAG |
|---|---|---|
|
Document Representation |
Flat, isolated text chunks |
Unified Tree (Hierarchy) + Graph (Entities) |
|
Indexing Method |
Vector Embeddings |
BookIndex (Logical layout + GT-Links) |
|
Retrieval Mechanism |
Static Top-K Similarity Search |
Dynamic, Agent-driven (IFT-inspired) |
|
Contextual Awareness |
Low (Loses document hierarchy) |
High (Preserves parent/child context) |
|
Best Suited For |
Short docs, simple FAQs, wikis |
Books, manuals, complex PDFs, multi-hop QA |
|
Token Efficiency |
Often bloated due to over-retrieval |
Highly optimized via node pruning |
When to Use RAG vs BookRAG
Deciding between standard RAG and BookRAG depends entirely on your enterprise data infrastructure and the complexity of user queries.
When to Use Traditional RAG
Short-form content: Processing individual emails, short articles, or simple product descriptions.
Budget constraints: You need a lightweight, easily deployable system with minimal indexing overhead.
Fact-lookup: Queries are straightforward and explicitly stated within single paragraphs.
When to Upgrade to BookRAG
Long-form, structured documents: Legal contracts, academic papers, compliance handbooks, and dense technical manuals.
High-stakes reasoning: When a wrong answer due to lost context is unacceptable (e.g., healthcare protocols, financial auditing).
Complex user queries: If your users frequently ask multi-hop questions that require aggregating data across different chapters or tracing a concept’s evolution throughout a document.
Conclusion
RAG remains the baseline architecture for grounding LLMs with external data. However, as enterprise use cases demand deeper reasoning across complex documents, BookRAG emerges as a critical evolution.
The decision is not binary. It is strategic:
Use RAG for speed, scale, and flexibility
Use BookRAG for depth, structure, and accuracy
Organizations that align the right architecture with the right use case will unlock significantly higher ROI from their AI investments.
FAQs
What is the main difference between BookRAG and RAG?
BookRAG uses hierarchical, structured retrieval for long documents, while RAG relies on flat chunk-based retrieval.
Is BookRAG a replacement for RAG?
No. BookRAG is a specialized extension of RAG designed for specific use cases involving long-form content.
Is BookRAG a replacement for Vector Databases?
No. BookRAG still utilizes vector search as a foundational component for initial entity matching and semantic relevance. However, it augments the vector store with a structural tree and a knowledge graph (BookIndex), fundamentally changing how the data is organized and retrieved.
Turn Enterprise Knowledge Into Autonomous AI Agents
Your Knowledge, Your Agents, Your Control
Your Knowledge, Your Agents, Your Control
Latest Articles




