
What is an AI Agent Harness? 5 Core Pillars and How to build
- Publised April, 2026
-
Duc Nguyen (Dwight)
Discover what an AI agent harness is, why harness engineering is replacing prompt engineering, and how to build robust infrastructure for production AI agents.
Table of Contents
Toggle
Key Takeaways
-
The OS of AI: An agent harness is the execution infrastructure—the “operating system”—that manages how an AI model interacts with the real world, handling tool execution, memory, and state persistence.
-
Beyond Prompt Engineering: As models become commoditized, competitive advantage has shifted to “Harness Engineering”—building robust, constraint-driven environments that ensure reliability.
-
The 5 Core Pillars: A production-grade harness requires tool orchestration, context compaction, task delegation, strict guardrails (Human-in-the-Loop), and deep observability.
-
Security by Design: Harnesses protect your systems by executing agent-generated code in isolated sandboxes (like Docker) and enforcing explicit permission boundaries.
Introduction
In enterprise AI, the biggest bottleneck is no longer the intelligence of Large Language Models (LLMs). It is the infrastructure connecting that intelligence to your business environment. Enter the agent harness.
As enterprise AI solutions mature in 2026, we are witnessing a massive paradigm shift. The data is clear: the difference between a brittle research prototype and a reliable, production-ready autonomous agent is not the prompt – it is the quality of its harness.
This comprehensive guide breaks down exactly what an agent harness is, why your engineering team needs to master “harness engineering,” and how to architect a system that guarantees security, scalability, and performance.
What is an Agent Harness?
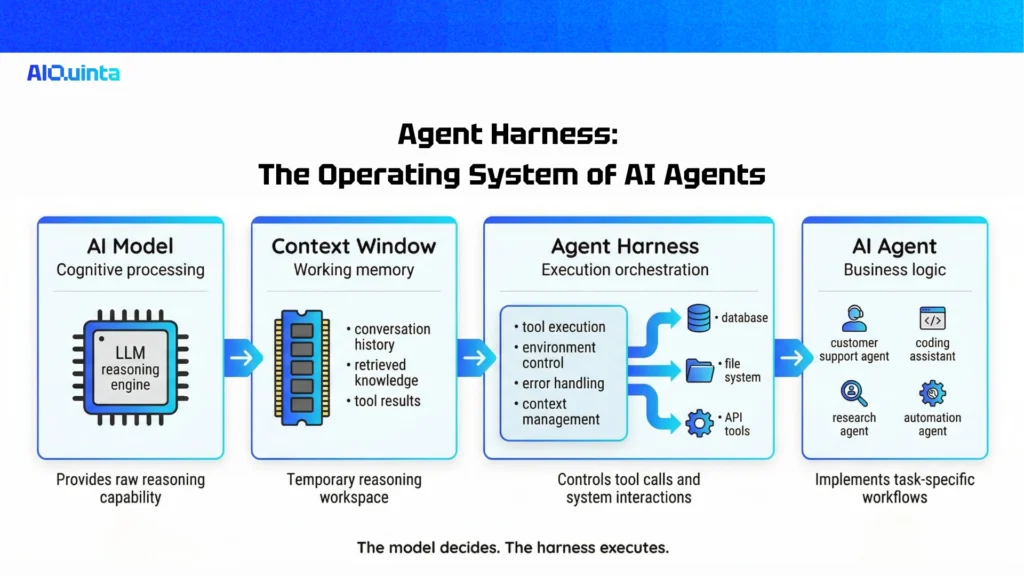
An agent harness is the software infrastructure surrounding an AI model that manages long-running tasks. It acts as the intermediary between the LLM’s reasoning engine and the outside world.
If we use a computing analogy to understand modern AI architecture:
-
The Model is the CPU: It provides the raw cognitive processing power.
-
The Context Window is the RAM: It is the limited, volatile working memory.
-
The Agent Harness is the Operating System: It curates the context, handles the “boot” sequence, provides standard drivers (tool handling), and governs execution.
-
The Agent is the Application: It is the specific user logic running on top of the OS.
The harness does not reason; it executes. When an AI agent decides it needs to read a file or query a database, the model itself cannot perform the action. It requests a tool call. The harness pauses the model, safely executes the request in a controlled environment, captures the raw output (or errors), and feeds that reality back into the model’s context window.
Agent Framework vs. Agent Harness
It is easy to confuse frameworks with harnesses. Here is a clear breakdown:
| Feature | Agent Framework (e.g., LangChain, AutoGen) | Agent Harness |
|---|---|---|
|
Primary Function |
Provides developer building blocks, abstractions, and standard APIs. |
Manages the live execution, safety constraints, and real-world feedback loops. |
|
Focus |
How the code is written and structured. |
How the agent interacts with the host environment and user. |
|
Analogy |
The programming language/SDK (e.g., .NET, Python). |
The runtime environment and sandbox (e.g., CLR, Docker). |
Why "Harness Engineering" is the Future of Enterprise AI
We are officially moving past the era of prompt engineering. “Harness engineering” is now a recognized discipline – the practice of designing the systems, constraints, and feedback loops that wrap around AI agents to make them reliable in production.
Here is why enterprise teams are investing heavily in harness infrastructure:
1. Surviving the “Bitter Lesson” of AI
Models are upgraded frequently. Logic that required complex, hand-coded pipelines in 2024 can now be handled natively by a single context-window prompt in 2026. If you over-engineer the agent’s internal control flow, the next model update will break your system. A lightweight harness abstracts the infrastructure away from the LLM, allowing developers to easily swap out the underlying “CPU” without rewriting the “Operating System.”
The Power of Feedback Loops
An agent is essentially a suggestion engine until it is grounded in reality. The harness provides the crucial execution loop: Try → Fail → Observe → Improve. By feeding raw, unedited errors back to the model, the harness forces the agent to self-correct, dramatically increasing success rates on complex coding and data tasks.
Creating Service Templates for AI
As noted by software architecture thought leaders, harnesses are becoming the new “service templates.” Instead of every application being a snowflake, enterprise teams can choose from a set of pre-built harnesses tailored to common topologies – complete with custom linters, structural tests, and standardized boundaries – ensuring AI-generated code remains maintainable at scale.
The 5 Core Pillars of a Production Agent Harness
Tool Orchestration & Sandboxed Execution
An agent’s capability is defined by the tools it can access. Tool orchestration means defining exactly which tools are available (APIs, databases, web search) and how they are invoked.
-
Virtual Filesystems: The harness provides a configurable virtual filesystem, ensuring the agent can read and write files without touching the host system’s root directory.
-
Sandboxing: When an agent writes code, it needs to test it. Harnesses execute this code in isolated environments (like ephemeral Docker containers) to prevent malicious commands or runaway resource consumption on your local machines.
Context Compaction and Memory Management
Deep agents handling long-running, multi-step tasks will eventually hit their token limits. The harness manages this via “Context Engineering.”
-
Compaction: Automatically summarizing and pruning older, less relevant conversation history while retaining critical system prompts and immediate context.
-
State Offloading: Pushing persistent memories and completed sub-tasks to durable storage (like a vector database), ensuring the agent stays within its token budget without losing its train of thought.
Task Delegation and Ephemeral Sub-Agents
For highly complex workflows, a single agent thread becomes cluttered. The harness enables the main routing agent to spin up stateless “sub-agents.”
-
Context Isolation: The sub-agent gets a clean context window dedicated solely to a specific sub-task.
-
Parallel Execution: Multiple sub-agents can run concurrently, speeding up the workflow.
-
Token Efficiency: Once the sub-agent finishes, the harness compresses its work into a single final report and returns it to the main agent.
Guardrails, Safety, and Human-in-the-Loop (HITL)
Full AI autonomy is rarely appropriate in enterprise settings. Guardrails are the deterministic rules that prevent agents from taking harmful actions.
-
Permission Boundaries: Strict rules defining what the agent cannot touch.
-
Validation Checks: Harnesses run agent outputs through traditional linters and test suites before accepting them.
-
Human-in-the-Loop: The harness can pause execution at critical junctures (e.g., before dropping a database table or sending an email) to require explicit human approval
Observability and Error Recovery
Production agents will inevitably fail. The harness ensures they fail gracefully.
-
Automated Retry Logic: Escalating retry strategies for network timeouts or API rate limits.
-
Loop Detection: Identifying when an agent is stuck repeating the same erroneous action and forcing a pivot.
-
Deep Telemetry: Logging every tool call, tracking token costs, recording decision trees, and surfacing anomalies. This turns vague agent behaviors into structured, debuggable data.
How to Build and Deploy Your First Agent Harness
If you are ready to move from prototype to production, follow this architectural checklist to deploy a robust harness.
Enterprise Harness Deployment Checklist
-
Define the Scope: Write an explicit permissions manifest detailing exactly what the agent should and should not be able to do.
-
Set Up the Workspace: Create a fresh, isolated directory or Docker container for every agent run. Treat it like a tiny, disposable project repo.
-
Establish the Execution Loop: Build the routing logic: Task comes in → Model requests tool → Harness executes tool in sandbox → Harness returns raw result → Model updates plan.
-
Implement the Gatekeeper: Add an intercept layer for destructive actions that pauses the loop and pings a human via Slack, Teams, or CLI for approval.
-
Build to Delete: Keep your harness modular. Do not over-engineer the control flow; rely on the model’s reasoning capabilities, and ensure your harness is ready to adapt when the next generation of foundational models drops.
The Future: Natural-Language Agent Harnesses (NLAHs)
The bleeding edge of harness engineering in 2026 is the development of Natural-Language Agent Harnesses (NLAHs). Historically, harness logic has been scattered across controller code, hidden framework defaults, and runtime-specific assumptions.
NLAHs propose a new standard: expressing harness behavior—role boundaries, state semantics, and failure handling—in editable, plain-text natural language. This structured representation is then executed by an Intelligent Harness Runtime (IHR). This decoupling allows non-engineers to adjust the operational constraints of an AI system simply by editing a text document, drastically lowering the barrier to entry for enterprise AI adoption.
Conclusion
The era of trusting an LLM to magically output flawless, multi-step workflows in a vacuum is over. The true differentiator for enterprise AI solution providers is the agent harness. By treating the AI model as a raw cognitive engine and surrounding it with robust execution loops, strict guardrails, and deep observability, organizations can finally unlock the promise of autonomous agents. Invest in harness engineering today, and you build resilient infrastructure that will easily adapt to the foundational models of tomorrow.
FAQs
What is the difference between an AI agent and an agent harness?
The AI agent is the application logic and the intelligence (powered by the LLM) that decides what actions to take. The agent harness is the surrounding infrastructure—the virtual environment, tool executors, and safety checkpoints—that actually performs those actions in the real world and reports back to the agent.
Why do I need “context compaction” in my harness?
As agents work on long-running tasks, their conversation history grows. If the history exceeds the model’s context window (token limit), the AI will crash or “forget” its original instructions. Context compaction automatically summarizes older logs and removes redundant information, keeping the agent focused and saving on API token costs.
What is a Natural-Language Agent Harness (NLAH)?
An NLAH is an emerging architectural pattern where the operational constraints, memory management rules, and failover states of the harness are defined in plain natural language rather than hard-coded in Python or C#. This allows teams to manage complex AI infrastructure through readable, easily editable text contracts.
Turn Enterprise Knowledge Into Autonomous AI Agents
Your Knowledge, Your Agents, Your Control
Your Knowledge, Your Agents, Your Control
Latest Articles




